
| |
ระบบฐานข้อมูลแบบกระจาย
ความหมายและแนวคิดเบื้องต้น
เราอาจให้คำจำกัดความของ ฐานข้อมูลแบบกระจาย ได้ว่าเป็นกลุ่มของฐานข้อมูลหลายตัวที่เกี่ยวข้อง หมายถึง ระบบซอฟต์แวร์ที่ยอมให้มีการจัดการฐานข้อมูลแบบกระจายได้ และทำให้ผูใช้มองไม่เห็นการกระจาย
วัตถุประสงค์ของฐานข้อมูลแบบกระจาย
หลักการพื้นฐานของฐานข้อมูลแบบกระจาย สำหรับผู้ใช้นั้น ระบบกระจายควรจะให้เขามองเห็นเหมือนกับระบบที่ไม่ได้กระจาย กล่าวอีกอย่างก็คือ ผู้ใช้ฐานข้อมูลในระบบกระจาย ควรจะสามารถทำสิ่งต่างๆได้เหมือนกับว่าระบบที่ใช้อยู่นั้นไม่ใช่ระบบกระจาย โดยเฉพาะอย่างยิ่งการกระทำที่เป็นการจัดกระทำข้อมูล
จากหลักการพื้นฐานดังกล่าวข้างต้นจึงนำไปสู่กฎเกณฑ์ย่อย หรือวัตถุประสงค์ 12 ประการดังนี้
- ความเป็นอิสระเฉพาะที่ (Local Autonomy) หมายความว่าที่ตั้งฐานข้อมูลแห่งหนึ่งในระบบกระจาย เป็นที่ตั้งที่มีข้อมูลเฉพาะที่ของตนและบริหารจดการข้อมูลด้วยตนเอง แม้ว่าผู้ที่ใช้อยู่ ณ ที่ตั้งอื่นๆจะขอดูได้ ก็จะต้องอยู่ภายใต้ความปลอดภัย ความถูกต้องของข้อมูล และการจัดเก็บของที่ตั้งเฉพาะ
- ต้องไม่มีที่ตั้งใดทำหน้าที่เป็นศูนย์กลาง (No Reliance on a Central Site) กล่าวคือ ไม่มีที่ตั้งแห่งใดแห่งหนึ่งที่ทำหน้าที่เป็นนายหรือบ่าว ที่ตั้งฐานข้อมูลแต่ละแห่งจะได้รับการปฏิบัติด้วยความเสมอภาคกัน
- การปฏิบัติงานอย่างต่อเนื่องไม่หยุดชะงัก (Continuous Operation) การที่มีที่ตั้งฐานข้อมูลหลายแห่งจะช่วยให้มีความน่าเชื่อถือและเตรียมการให้บริการที่สูงขึ้น เช่น ความเป็นไปได้ที่ระบบจะถูกเปิดขึ้นมาทำงานได้ทุกเมื่อ และความเป็นไปได้ที่ระบบจะทำงานตลอดเวลาในช่วงที่ให้บริการ
- ความป็นอิสระจากที่ตั้ง หรือการมองผ่านสถานที่ตั้ง (Location Independence or Location Transparency) ผู้ใช้ไม่ควรจะรับรู้ว่าข้อมูลจริงทางกายภาพถูกจัดเก็บไว้ ณ ที่ตั้งใด แต่ผู้ใช้ควรจะสามารถกระทำการใดๆ ได้เหมือนกับว่าข้อมูลนั้นถูกเก็บไว้ ณ ที่ตั้งของตนนั้น
- ความเป็นอิสระจากการแบ่งเป็นชิ้นส่วนย่อย หรือการมองผ่านชิ้นส่วนย่อย (Fragmetation Independence or Fragmentation Transparency) ในระบบกระจาย ข้อมูลอาจถูกแบ่งเป็นชิ้นส่วนย่อยหลายชิ้นเก็บไว้ ณ ที่ตั้งคนละแห่งกันหรือที่ตั้งเดียวกันแต่ละคนแต่ละเครื่อง เพื่อประโยชน์ในการลดความแออัดในการสัญจรสื่อสารข้อมูล โดยอาจแบ่งข้อมูลในรีเลชั่นออกได้เป็น 2 แบบ คือ ชิ้นส่วนย่อยแนวนอน และชิ้นส่วนย่อยแนวตั้ง ซึ่งสอดคล้องกับการทำ Restriction และ projection จุดสำคัญ คือ ผู้ที่ใช้ไม่ควรจะรับรู้ว่าข้อมูลจริงทางกายภาพถูกแบ่งชิ้นส่วนไว้กี่ชิ้น ณ ที่ใดบ้าง แต่ผู้ใช้ควรจะสามารถกระทำการใด ๆ ได้เหมือนกับว่าข้อมูลนั้นถูกเก็บไว้เป็นก้อนเดียวกันเท่านั้น
- ความเป็นอิสระจากการเก็บซ้ำชุดข้อมูล หรือ การมองผ่านการเก็บชุดข้อมูลซ้ำ (Replication Independce or Replication Transparency) ในการเก็บชุดข้อมูลซ้ำไว้ ณ ที่ตั้งหลายแห่ง มีเหตุผลอย่างน้อยสองประการ คือ ประการแรกต้องการเพิ่มประสิทธิภาพ หรือ Performance โดยโปรแกรมสามารถทำงานกับสำเนาที่ถูกเก็บอยู่ ณ ที่ตั้งของตน หรือที่ตั้งอยู่ใกล้ที่สดดีกว่าที่จะต้องทำการติดต่อไปยังที่ตั้ง ณ ที่ห่างไกล ประการที่สองการเก็บชุดข้อมูลซ้ำทำให้การเตรียมให้บริการที่ดีกว่า
- การติดต่อประมวลผลสอบถามแบบกระจาย (Disteributed Query Processing) มีลักษณะสองประการเลยคือ ประการแรกการสอบถามข้อมูลที่ไม่มีอยู่ ณ ที่ตั้งของตนจะต้องสามารถทำได้และประหยัดค่าใช้จ่ายและเวลาในการสื่อสารมากกว่าระบบการรับส่งข้อมูลปรกติซี่งเป็นแบบครั้งละระเบียน
- การจัดการธุรกรรมแบบกระจาย ( Distributed Transaction Management ) คือ การควบคุมฟื้นสภาพ และการควบคุมสภาวะพร้อมกัน ซึ่งในระบบฐานข้อมูลแบบกระจายจะต้องมีการเพิ่มความสามารถในการควบคุม ในการควบคุมภาวะพร้อมกับของระบบกระจายจะต้องมีการใช้ล็อก
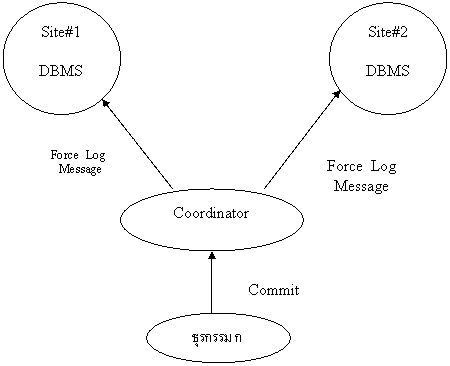
ในภาพแรกนี้ธุรกรรม ก เป็นผู้ออกคำสั่งให้กระทำ เพื่อบันทีกผลการทำงานของธุรกรรม ก ที่ผ่านมาทั้งหมดลงสู่สื่อเก็บข้อมูลในฐานข้อมูล ตัวประสานงาน ( Coordinator ) จะส่งข้อความแจ้งไปยังตัวแทนเพื่อบอกระบบบริหารข้อมูล ณ ที่ตั้งต่าง ๆ ว่าให้บันทึกงานที่ผ่านมาลงบนแฟ้มปูม ( Log File ) ของฐานแต่ละแห่ง
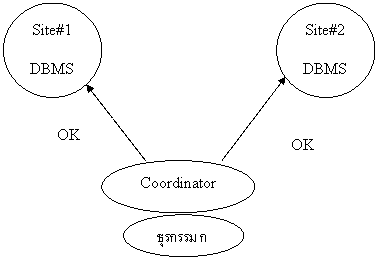
ภาพที่สอง หลังจากที่ระบบบริหารฐานข้อมูลทำการบันทึกแฟ้มปูนแล้วเป็นที่เรียบร้อยทุกแห่ง
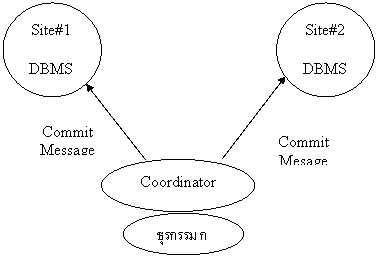
ภาพที่สาม หลังจากที่ได้รับคำตอบว่า เรียบร้อย ตัวประสานงานจึงตัดสินใจสั่งให้ทุกที่ตั้งทำ COMMIT พร้อมกัน ซึ่งเป็นข้อตกลงว่าทุกแห่งจะต้องทำตามบัญชา
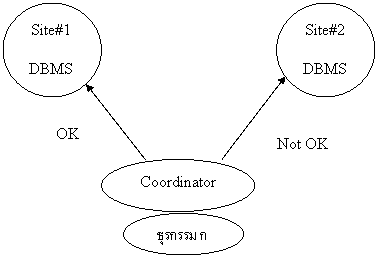
ภาพที่สี่ หลังจากตัวประสานงานสั่งบันทึกแฟ้มปูนแล้ว แต่ระบบบริหารฐานข้อมูลของที่ตั้งแห่งใดแห่งหนึ่งไม่สามารถทำได้
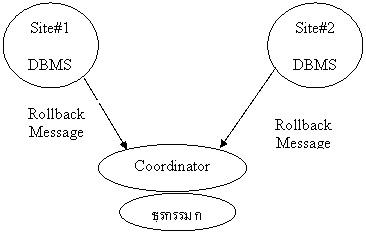
ภาพที่ห้า เมื่อได้รับคำตอบว่า ไม่เรียบร้อย ตัวประสานงานจึงตัดสินใจสั่งให้ทุกที่ตั้งทำ ROLLBACK พร้อมกัน ซึ่งเป็นข้อตกลงว่าทุกแห่งต้องทำตามบัญชาเดียวกัน
9.ความเป็นอิสระจากฮาร์ดแวร์ (Hardware Independence ) คือ เครื่องคอมฯที่นำมาใช้ในระบบฐานข้อมูลแบบกระจาย แม้ว่าจะต่างยี่ห้อต่างชนิดกันไปในแต่ละที่ตั้งหรือแต่ละแห่งก็ตาม
10. ความเป็นอิสระจากระบบปฏิบัติการ (Operting System Independence) หมายความว่า ถ้าเครื่องคอมพิวเตอร์ที่ตั้งฐานข้อมูล 3 แห่งในระบบฐานข้อมูลแบบกระจายมีการใช้ระบบปฏิบัติการแตกต่างกัน
11. ความเป็นอิสระจากเครือข่าย (Network Independence) ถ้าที่ตั้งฐานข้อมูลแต่ละแห่งในระบบฐานข้อมูลแบบกระจายมีลักษณะเครือข่ายไม่เหมือนกัน ความแตกต่างนั้นต้องไม่เป็นอุปสรรคในการทำงานร่วมกัน
12. ความเป็นอิสระ จากระบบบริหรฐานข้อมูล (DBMS Independence) สื่งที่ต้องการตามวัตถุประสงค์ข้อนี้คือ โปรแกรมระบบบริหารฐานข้อมูลที่ติดตั้งบนเครื่องคอมพิวเตอร์ของที่ตั้งฐานข้อมูล ณ ที่ต่าง ๆ แม้ว่าจะเป็นโปรแกรมคนละยี่ห้อกัน กล่าวคือแม้ว่าระบบฐานข้อมูลแบบกระจายจะเป็นระบบหลากหลายแต่ต้องสามารถติดต่อสื่อสารและทำงานร่วมกันได้
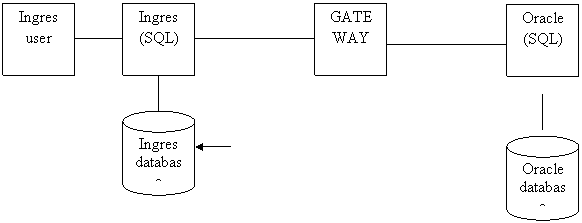
![]() Distributed lngres database
Distributed lngres database
Gateway ของ Ingeres ช่วยเชื่อมประสานทำให้ Oracle เหมือน Ingres
10.3 ประโยชน์ของฐานข้อมูลแบบกระจาย มีดังนี้คือ
- มีความเป็นอิสระเฉพาะที่ (Local Autonomy) ซึ่งตรงกับวัตถุประสงค์ในหัวเรื่องที่ผ่านมาเนื่องจากข้อมูลที่ผู้ใช้กลุ่มหนึ่งมักต้องใช้เสมอถูกนำมาไว้ ณ ที่ตั้งที่พวกเขาทำงานอยู่และทำให้พวกเขาสามารถควบคุมได้ในที่ตั้ง
- ประสิทธิภาพที่ดีขึ้น (Impoved Performance) เนื่องจากที่ตั้งของฐานข้อมูลดูแลรับผิดชอบเฉพาะส่วนของฐานข้อมูลทั้งหมดขององค์การเท่านั้น ทำให้ความหนาแน่น ของงานที่หน่วยประมวลผลกลางต้องทำ และบริการเกี่ยวกับการนำเข้าและส่งข้อมูลออก
- ความเชื่อถือได้และความพร้อมบริการที่ดีขึ้น ถ้าข้อมูลมีการทำสำเนาซ้ำเก็บไว้มากกว่าหนึ่งที่ตั้ง ในกรณีที่เกิดความขัดข้อง ณ ที่ตั้งหนึ่ง หรือสัญญาณการสื่อสารใช้ไม่ได้ ย่อมมีทางอื่นที่จะเรียกค้นหาข้อมูลของที่ตั้งนั้นขึ้นมาได้
- ความประหยัด (Economics) เราอาจมองความประหยัดได้สองมุม มุมแรกคือประหยัดค่าใช้จ่ายในการสื่อสาร มุมที่สองคือ ประหยัดค่าใช้จ่ายในการซื้อเครื่องคอมพิวเตอร์ขนาดเล็กหลาย ๆเครื่อง ซึ่งสามารถทำงานได้กับเครื่องคอมพิวเตอร์ขนาดใหญ่เครื่องเดียว
- ความสามารถที่จะขยายระบบ (Expandabiltity) ในสภาพแวดล้อมแบบกระจายการขยายขนาดฐานข้อมูลจะทำได้ง่ายกว่า เพราะแทบไม่จำเป็นต้องมีการยกเครื่องขนาดใหญ่แต่อย่างใด เพียงแค่เพิ่มหน่วยประมวลผลและสื่อเก็บข้อมูลเข้าไปในเครือข่าย หรืออาจเพิ่มเครื่องคอมพิวเตอร์ขนาดเล็กเพียงเครื่องเดียวไปในเครือข่ายก็สามารถขยายระบบได้
- ความสามารถในการแบ่งปัน (Shareability) ในองค์การที่มีสาขากระจายกันไปตามเมือง จังหวัด หรือรัฐต่าง ๆ การที่จะแบ่งปันทรัพยากร และข้อมูลได้นั้นย่อมต้องอาศัยระบบการกระจาย ซึ่งจะทำให้การแบ่งปันนั้นยืดหยุ่นมากกว่าระบบรวมศูนย์
10.4 ปัญหาและข้อเสียการเปรียบเทียบของระบบฐานข้อมูลแบบกระจาย
10.4.1 ปัญหาของระบบข้อมูลแบบกระจาย
วัตถุประสงค์และแนวคิดของระบบฐานข้อมูลแบบกระจายที่ได้อธิบายมานั้นทำให้สรุปได้ประการหนึ่ง คือ ต้องการให้ผู้ใช้ที่อยู่ห่างไกลสามารถประมวลผลได้เหมือนผู้ใช้ที่อยู่ใกล้ ซึ่งในความเป็นจริงเป็นเครือข่ายบริเวณกว้าง (WAN) ซึ่งต้องอาศัยสายสื่อสารสาธารณะเช่น สายโทรศัพท์ ซึ่งมีอัตราการส่งข้อมูลประมาณ 5,000 ถึง 10,000 ไบท์ต่อวินาที ในขณะที่ฮาร์ดดิสก์มีอัตราการโอนย้ายข้อมูลประมาณ 5 ถึง 10 ล้านไบท์ต่อวินาที ซึ่งถือว่าห่าง ชั้นกันมาก ดังนั้นวัตถุประสงค์ของระบบฐานข้อมูลแบบกระจายจึงมุ่งไปที่การลดการใช้เครือข่ายลงให้ใช้น้อยที่สุด
( To minimize network utilization) ซึ่งการทำเช่นนี้ส่งผลให้เกิดปัญหาตามมาดังต่อไปนี้
1. การประมวลผลสอบถาม (Query Processing) ปัญหาด้านการประมวลผลสอบถามเกิดจากการที่พยายามลดการติดต่อผ่านระบบเครือข่ายให้เหลือน้อยที่สุด (Query Optimization) ซึ่งอาจทำให้มีขั้นตอนในการประมวลผลที่ยุ่งยากและทำให้เสียเวลาและค่าใช้จ่ายสูงกว่าระบบรวมศูนย์
2. การจัดการพจนานุกรมข้อมูล ( Catalog Management) ปัญหาด้านการจัดการพจนานุกรมข้อมูลในระบบกระจายเกิดจากการที่จะตัดสินใจเก็บมันไว้ที่ไหนและอย่างไร เนื่องจากมีข้อมูลเกี่ยวกับฐานข้อมูลมากกว่าระบบรวมศูนย์ และมีการแยกกระจายเข้ามาอีกปัจจัยหนึ่ง ซึ่งต้องมีมาเก็บข้อมูลการควบคุม (Control Intormation) เอาไว้ด้วย เช่น ข้อมูลที่ตั้ง ชิ้นส่วนข้อมูล และสำเนาซ้ำของข้อมูล เป็นต้น มีแนวทางการจัดเก็บหลายวิธี ได้แก่ การจัดเก็บไว้ที่ศูนย์รวมทั้งหลาย การจัดเก็บพจนานุกรมข้อมูลทั้งหมดไว้ทุกที่ตั้ง การจัดเก็บเพียงบางส่วนไว้ที่สาขาที่ใช้ข้อมูล หรือแบบประสมระหว่างการจัดเก็บไว้ที่ศูนย์รวมทั้งหมดและจัดเก็บเพียงบางส่วนไว้ที่สาขา
3. การปรับปรุงข้อมูลให้ถูกต้องตามกัน (Update Propagation) ปัญหาการปรับปรุงข้อมูลให้ถูกต้องตามกันนี้เกิดจากการที่ระบบยอมให้มีสำเนาข้อมูลซ้ำเก็บไว้ในที่ตั้งต่าง ๆ กันได้ ตัวอย่างเช่น สาขาเชียงใหม่ และสาขาระยอง มีการเก็บข้อมูลชุด ต ซ้ำกัน ถ้าสาขาเชียงใหม่มีผู้ทำการปรับปรุงข้อมูล ต แล้วจะต้องนำเอาข้อมูลชุด ต ที่เปลี่ยนแปลงแล้วนี้ไปปรับปรุงให้กับสาขาระยอง ถ้าบังเอิญเกิดเหตุขัดข้องทำให้ไม่สามารถปรับปรุงข้อมูล ต ณ สาขาระยองได้ ก็จะทำให้เกิดความไม่ถูกต้องขึ้นในระบบ โดยเฉพาะที่สาขาระยอง
4. การควบคุมการฟื้นสภาพ (Recovery Control ) ปัญหาด้านการควบคุมการฟื้นสภาพนี้อธิบายไว้บ้างแล้วในหัวข้อวัตถุประสงค์ของระบบฐานข้อมูลแบบกระจาย กล่าวคือ จะต้องมีตัวแทน (Agent ) มีข้อตกลงกระทำสองระยะ (Two – phase Commit Protocol ) และมีตัวประสานงาน (Coordinator) ซึ่งยุ่งยากซับซ้อนกว่าระบบรวมศูนย์
5. การควบคุมภาวะพร้อมกัน (Concurrency Control) ปัญหาด้านการควบคุมภาวะพร้อมกันนี้ได้อธิบายไว้บ้างแล้วเช่นกัน กล่าวคือ ต้องมีการล็อก (Locking) ซึ่งเหมือนกับระบบรวมศูนย์แต่ต่างกันคือการกระทำใด ๆ เกี่ยวกับการล็อก ได้แก่ การร้องขอ การทดสอบ การเซต และการปล่อยล็อก ล้วนแต่เพิ่มค่าใช้จ่าย เนื่องจากต้องมีการส่งข้อความ (Message)ไปมาระหว่างที่ตั้งสาขาที่สื่อสารกัน ความยุ่งยากจะเกิดขึ้นเมื่อต้องมีการปรับปรุงวิธีการส่งข้อความ เช่น เอาการร้องขอมารวมกับการปรับปรุงข้อมูล แล้วส่งไปพร้อมกัน ซึ่งเรียกว่าวิธีขนลูกหมูขึ้นรถ (Piggybacking) ซึ่งแม้จะทำถึงขนากนี้แล้วก็ยังไม่สามารถรับประกันได้ว่าระบบกระจายจะเร็วเท่าระบบรวมศูนย์ ปัญหาสำคัญอีกประการหนึ่งก็คือ การล็อกในระบบกระจายอาจนำไปสู่วงจรแบบรวม(Globak Deadlock )
ซึ่งเป็นวงจรอับที่เกี่ยวข้องกับที่ตั้งสองแห่งขึ้นไปดังภาพ
สาขาเชียงใหม่
ถือครองล็อก ต.1
รอคอยให้ ธ.1
ปล่อย ต.1
ธ2
ธ1
![]()
![]()
![]()
รอคอยให้ ธ.3 รอคอยให้ ธ.2 ทำเสร็จ
ทำเสร็จ
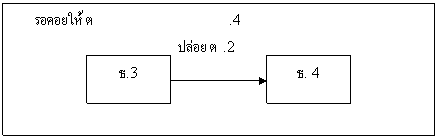
สาขาระยอง
ภาพแสดงตัวอย่างวงจรอับแบบรวม
10.4.2 ข้อเสียเปรียบของระบบฐานข้อมูลแบบกระจาย
ต่อไปนี้เป็นข้อเสียเปรียบที่เกิดจากปัญหาหลากประการของการกระจายฐานข้อมูล ดังที่กล่าวมา
1. ความซับซ้อน ( Complexity) ปัญหาที่เกิดขึ้นในระบบฐานข้อมูลแบบกระจายโดยธรรมชาติแล้วมีความสลับซับซ้อนมากกว่าระบบฐานข้อมูลธรรมดาเพราะนอกจากจะมีปัญหาของระบบฐานข้อมูลธรรมดาแล้วยังมีปัญหาที่ยังแก้ไม่ตกแบบใหม่ ๆ อีกด้วย เช่น ในเรื่องของการควบคุมภาวะพร้อมกัน การควบคุมการฟื้นสภาพ และการปรับปรุงข้อมูลให้สอดคล้องกัน เป็นต้น
2. การขาดประสบการณ์ (Lock of Experience) เนื่องจากยังมีผู้ใช้ระบบฐานข้อมูลแบบกระจายน้อยกว่าระบบรวมศูนย์อยู่มาก จึงทำให้มีโปรแกรมประยุกต์ใช้น้อย มีผู้เชี่ยวชาญที่มีประสบการณ์น้อยกว่า องค์การที่มีการใช้ระบบฐานข้อมูลแบบกระจายในระยะเริ่มแรก คือ สายการบิน (ระบบจองตั๋ว)
3. ค่าใช้จ่าย (Cost) ระบบกระจายจำเป็นต้องมีฮาร์ดแวร์เพิ่มเติมเข้ามา โดยเฉพาะหน่วยงานที่ไม่เคยมรการประมวลผลแบบกระจายมาก่อนจะต้องเพิ่มอุปกรณ์สื่อสาร เป็นต้น ประการที่สองคือค่าใช้จ่ายด้านซอฟต์แวร์ทั้งทางด้านระบบบริหารฐานข้อมูลแบบกระจายแบะทางด้านสื่อสารเพื่อช่วยแก้ปัญหาทางเทคนิคอีกด้วย ประการสุดท้ายคือค่าใช้จ่ายด้านแรงงาน โดยเฉพาะการทำสำเนาข้อมูลซ้ำ และการบำรุงรักษาระบบเป็นต้น ในกรณีนี้ผลกำไรที่สูงขึ้นต้องชั่งน้ำหนักกับค่าใช้จ่ายด้านบุคลากรในส่วนนี้ที่ต้องเพิ่มขึ้น
4. การกระจายการควบคุม (Distribution of Control) ประเด็นนี้อาจถือได้ว่าเป็นทั้งประโยชน์และข้อเสียเปรียบของระบบฐานข้อมูลแบบกระจาย ทั้งนี้เพราะเป็นเหมือนดาบสองคม การกระจายการควบคุมจะสร้างปัญหาเรื่องภาวะพร้อมกันและการประสานงาน ( Synchronization and Coordination) นอกจากนั้นแล้วหากไม่มีการเอาใจใส่ที่ดีพอในเรื่องของนโยบายด้านการควบคุม อาจทำให้เกิดเป็นภาระผูกพันขึ้นมาให้หนักใจแก่ผู้บริหาร
5. ความปลอดภัย ( Security) เปรียบเทียบกับระบบฐานข้อมูลแบบรวมศูนย์ซึ่งมีประโยชน์ในเรื่องความสะดวกและง่ายในด้านการรักษาความปลอดภัยในการเข้าถึงข้อมูลเพราะระบบบริหารฐานข้อมูล ณ ที่ตั้งแห่งเดียวย่อมสามารถบังคับใช้กฎเกณฑ์ ในการเข้าถึงข้อมูลได้ไม่ยาก ทว่าในระบบฐานข้อมูลแบบกระจาย มีสื่อกลางคือเครือข่ายเข้ามาเกี่ยวข้องซึ่งเป็นที่ทราบกันดีว่าการรักษาความปลอดภัยบนเครือข่ายคอมพิวเตอร์นั้นยังมีปัญหาอยู่มาก ดังนั้นจึงเห็นได้ชัดว่าปัญหาเรื่องความปลอดภัยในระบบฐานข้อมูลแบบกระจายโดยธรรมชาติแล้วมีความสลับซับซ้อนมากกว่าแบบรวมศูนย์แน่นอน
6. ความยากลำบากในการเปลี่ยนแปลง (Difficulty of Change ) เนื่องจากองค์การธุรกิจส่วนใหญ่ได้ลงทุนทำระบบฐานข้อมูลแบบรวมศูนย์ไปมากแล้ว และในปัจจุบันยังไม่มีเครื่องมือหรือระเบียบวิธีการใดที่จะช่วยให้ผู้ใช้แปลงฐานข้อมูลแบบรวมศูนย์ให้ออกมาเป็นระบบฐานข้อมูลแบบกระจายได้โดยตรงซึ่งต้องรองงานศึกษาวิจัยทางด้านฐานข้อมูลแบบหลากหลาย (Heterogeneous Databases) และ การบูรณาการฐานข้อมูล (Database Integration) ให้เอาชนะความยุ่งยากเหล่านี้ให้ได้ก่อน
|