
| |
ฐานข้อมูลเชิงสัมพันธ์
3.1 ลักษณะและรูปแบบของฐานข้อมูลเชิงสัมพันธ์
ฐานข้อมูลเชิงสัมพันธ์ (Relational Database) มีลักษณะ (Aspects) หรือส่วนที่สำคัญอยู่ 3 ลักษณะคือ
1. ลักษณะทางโครงสร้าง (Structural) ผู้ใช้ฐานข้อมูลเชิงสัมพันธ์นี้ จะรับรู้ในลักษณะที่ว่าข้อมูลในฐานข้อมูล จะอยู่ในรูปตาราง (Tables) ต่างๆ
2. ลักษณะความถูกต้อง (Integrity Aspect) ตารางต่างๆ ในฐานข้อมูลเชิงสัมพันธ์จะต้องเป็นไปตามข้อกำหนดเรื่องความถูกต้องของข้อมูล (Integrity Constraints)
3. ลักษณะด้านจัดดำเนินการ (Manipulative Aspect) ต้องมีตัวดำเนินการต่างๆ เตรียมไว้ให้แก่ผู้ใช้ในการสั่งกระทำการใดๆ กับตารางข้อมูล โดยจะมีตัวดำเนินการสำคัญ อยู่ 3 ตัว ได้แก่
1.1 Restrict Operation เป็นการดึงแถวข้อมูลเฉพาะบางแถวออกมาจากตาราง เช่น การใช้คำสั่ง Where (Condition)
1.2 Project Operation เป็นการดึงคอลัมน์ข้อมูลเฉพาะบางคอลัมน์ออกมาจากตาราง เช่น การใช้คำสั่ง Select (Column_Name)
1.3 Join Operation เป็นการเชื่อมตารางตั้งแต่ 2 ตารางขึ้นไปเข้าด้วยกันโดยมีค่าบางค่าในคอลัมน์ตรงกันเป็นหลัก ดังภาพ
DEPT
BEPTNO |
DNAME |
BUDGET |
D1 |
Marketing |
10000000 |
D2 |
development |
12000000 |
D3 |
Research |
5000000 |
DMP
EMPNO |
ENAME |
DEPTNO |
SALARY |
E1 |
Lopez |
D1 |
4000 |
E2 |
Cheng |
D2 |
4200 |
E3 |
Finzi |
D3 |
3000 |
E4 |
Satio |
D4 |
3500 |
Restrict:
DEPTs where BUDGET >8000000
ผลลัพธ์
DEPTNO |
DNAME |
SALARY |
D1 |
Marketing |
10000000 |
D2 |
Development |
12000000 |
Project:
DEPTs over DEPTNO, BUDGET
ผลลัพธ์
DEPTNO |
BUDGET |
D1 |
10000000 |
D2 |
12000000 |
D3 |
5000000 |
Join:
DEPTs and EMPs over DEPTNO
ผลลัพธ์
DEPTNO |
DNAME |
BUDGET |
EMPNO |
ENAME |
SALARY |
D1 |
Marketing |
10000000 |
E1 |
Lopez |
40000 |
D1 |
Marketing |
10000000 |
E2 |
Cheng |
42000 |
D2 |
Development |
12000000 |
E3 |
Finzi |
30000 |
D2 |
Development |
12000000 |
E4 |
Satio |
35000 |
ภาพแสดงตัวอย่างของการทำ Restrict, Project, และ Join
3.2 รีเลชั่นและเรลวาร์
รีเลชั่น (Relation) คือ คำเรียกตาราง (Table) ในเชิงคณิตศาสตร์ ระบบเชิงสัมพันธ์อาศัยตัวแบบเชิงสัมพันธ์ซึ่งเป็นทฤษฎีข้อมูลแนวนามธรรม (Abstract theory of data) ตามหลักการของคณิตศาสตร์ผู้ที่ว่างรากฐานของตัวแบบสัมพันธ์ (1969-1970) คือ E.F. Codd ปัจจุบันแนวคิดของเขาเป็นที่ยอมรับกันเป็นสากล มีอิทธิพลต่อเทคโนโลยีฐานข้อมูล, ปัญญาประดิษฐ์, การประมวลผลภาษาธรรมชาติ และการออกแบบระบบฮาร์ดแวร์อีกด้วย
เรลวาร์ (Relvar) ย่อมาจาก Relation Variables ซึ่งก็คือโครงสร้างของตารางนั่นเอง โดยคำว่า Variables หมายถึง ชื่อเขตข้อมูลหรือแอตทริบิวต์ (Attribute) ส่วนค่าหรือข้อมูลที่อยู่ในตารางแต่ละช่องนั้นเรียกว่า Relation Values
ตัวแบบเชิงสัมพันธ์จะมีชื่อเรียกสิ่งต่างๆ เกี่ยวกับตารางเป็นชื่อเฉพาะดังภาพต่อไปนี้
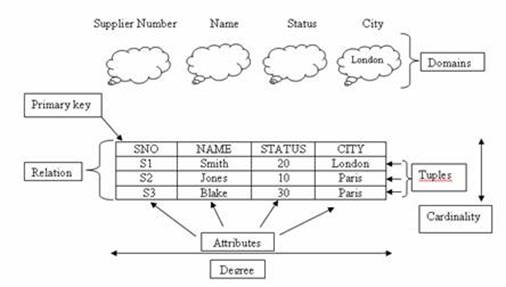
- โดเมน (Domain) หมายถึง สิ่งที่รวมค่าทั้งหมด (Pool of Values)
- คีย์หลัก (Primary Key) เป็นค่าที่ไม่ซ้ำกัน และใช้เป็นตัวกำหนดอื่นๆ
- ทูเพิล (Tuple) คือ แถวของข้อมูล ซึ่งในระบบแฟ้มข้อมูลเรียกว่า ระเบียน
- แอตทริบิวต์ (Attribute) คือ เขตข้อมูล คอลัมน์ หรือสดมภ์ของข้อมูล
- คาร์ดิแนลิตี้ (Cardinality) คือ จำนวนรวมของทูเพิลในแต่ละรีเลชั่น
- ดีกรี (Degree) คือ จำนวนรวมของสดมภ์ในแต่ละรีเลชั่น
3.3 คุณสมบัติของรีเลชั่น
รีเลชั่นหรือตาราง มีคุณสมบัติ 4 ประการ ดังนี้
1. ต้องไม่มี Tuple หรือแถวใดซ้ำกันกับแถวอื่น (There are no duplicate tuples) เนื่องจากรีเลชั่นเกิดจากการเอา Domain มาคูณกัน นอกจากนั้นข้อมูลในคีย์หลัก (Primary Key) จะต้องไม่ซ้ำ เช่น รหัสลูกค้าชื่อสมชาย ถึงแม้จะมี 3 คน แต่จะได้รหัสไม่ซ้ำกันเพราะเป็นคนละคนกัน
2. แต่ละแถวไม่จำเป็นต้องเรียงลำดับจากบนลงล่าง (Tuples are unordered, top to bottom) กล่าวคือ ไม่มีความแตกต่างของการเรียงแถวหรือไม่เรียงแถว เพราะ
c
b
a
a
b
c
และ ถือเป็นเซตเดียวกัน
3. แต่ละคอลัมน์ไม่จำเป็นต้องเรียงจากซ้ายไปขวา (Attributes are unordered, Left to right) เพราะ T1,T2,T3 = T2,T1,T3
4. แต่ละแถวต้องมีค่าเดียวในแต่ละคอลัมน์ (Each tuple contains exactly one value for each attribute) กล่าวคือ ต้องเป็น Atomic คือ ต้องมีค่าเดียว ต้องไม่เป็นเซตของค่าหลายค่า เช่น แยกชื่อ นามสกุลออกจากัน
ซึ่งคุณสมบัติข้อสุดท้ายนี้ทำให้ข้อมูลในตารางมีความเป็นปรกติหรืออยู่ในบรรทัดฐาน (Normalized) ซึ่งเทียบเท่ากับว่าอยู่ใน รูปแบบปกติหรือรูปแบบบรรทัดฐานขั้นที่ 1 (First Normal Form)
SSP
SNO |
SNAME |
STATUS |
CITY |
PQ |
S1 |
Smith |
20 |
London |
P1-300 |
S2 |
Jones |
10 |
Paris |
P1-300 |
S5 |
Adams |
30 |
Athens |
…. |
ภาพแสดงตารางข้อมูลที่ไม่มีคุณสมบัติข้อ 4
SNO |
SNAME |
STATUS |
CITY |
PNO |
QTY |
S1 |
Smith |
20 |
London |
P1 |
300 |
S1 |
Smith |
20 |
London |
P2 |
200 |
S1 |
Smith |
20 |
London |
P6 |
100 |
S2 |
Jones |
10 |
Paris |
P1 |
300 |
S2 |
Jones |
10 |
Paris |
P2 |
400 |
S2 |
Adams |
30 |
Athens |
… |
… |
ภาพแสดงตารางข้อมูลที่เป็นไปตามคุณสมบัติข้อ 4
3.4 พีชคณิตเชิงสัมพันธ์และแคลคูลัสเชิงสัมพันธ์
ทั้งพีชคณิตเชิงสัมพันธ์และแคลคูลัสเชิงสัมพันธ์ เป็นแนวคิดต้นกำเนิดของภาษาสอบถามเชิงโครงสร้าง (Structured Query Language : SQL) ซึ่งบริษัทไอบีเอ็มได้นำไปพัฒนาขึ้นในภายหลังจนกลายเป็นภาษามาตรฐานของระบบฐานข้อมูลในที่สุด
3.4.1 พีชคณิตเชิงสัมพันธ์ (Relational Algebra)
พีชคณิตเชิงสัมพันธ์เป็นภาคจัดกระทำของตัวแบบเชิงสัมพันธ์ (The Manipulative Part of the Relational Model) กล่าวคือ เป็นเซตของตัวดำเนินการ (Operators) ซึ่งจะนำเอารีเลชั่น (ตาราง) มาเป็นโอเปอแรนด์ (Operand) หรือตัวถูกกระทำ และจะให้ผลลัพธ์ออกมาเป็นอีกรีเลชั่นหนึ่ง การเขียนพีชคณิตเชิงสัมพันธ์นี้จะเป็นการสั่งทีละข้อ กล่าวคือ เป็นแบบ Prescriptive หรือเป็นแบบ How to ผู้เขียนต้องสั่งเชิงอธิบายเพื่อให้ได้ผลลัพธ์ออกมา มีลักษณะเป็นขั้นตอน (Procedural) เช่น
JOIN supplier and shipment tuples over SNO.
(จงเชื่อมแถวของตาราง supplier และ shipment เข้าด้วยกันตามค่าในคอลัมน์ SNO)
RESTRICT the result of that join to tuples for part P2
(เอาผลที่ได้มาคัดเอาเฉพาะที่มีค่าในคอลัมน์ part = P2)
PROJECT the result of that restriction over SNO and CITY
(นำเอาผลที่ได้มาแสดงเฉพาะคอลัมน์ SNO และ CITY)
SUPPLIER
SNO |
SNAME |
STATUS |
CITY |
S1 |
Smith |
20 |
London |
S2 |
Jones |
10 |
Paris |
S3 |
Blake |
30 |
Paris |
S4 |
Clark |
20 |
London |
S5 |
Adams |
30 |
Athens |
SHIPMENT
SNO |
PNO |
QTY |
S1 |
P1 |
300 |
S1 |
P2 |
200 |
S1 |
P3 |
400 |
S1 |
P4 |
200 |
S1 |
P5 |
100 |
S1 |
P6 |
100 |
S2 |
P1 |
300 |
S2 |
P2 |
400 |
S3 |
P2 |
200 |
S4 |
P2 |
200 |
S4 |
P4 |
300 |
S4 |
P5 |
400 |
การดำเนินการของพีชคณิตเชิงสัมพันธ์จะมี 8 ตัวดำเนินการใน 2 กลุ่ม คือ
1. ตัวดำเนินการเซตแบบดั้งเดิม ได้แก่ UNION, INTERSECTION, DIFFERENCE, Cartesian, PRODUCT
2. ตัวดำเนินการเชิงสัมพันธ์พิเศษ ได้แก่ RESTRICT, PROJECT, JOIN, DIVIDE ซึ่งมีลักษณะการดำเนินการดังภาพต่อไปนี้
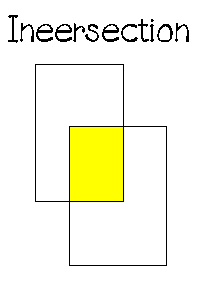
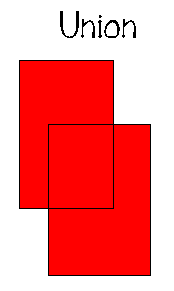
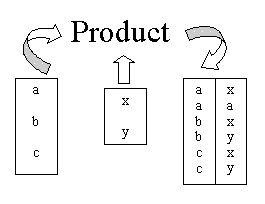
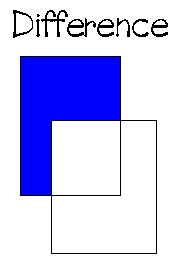


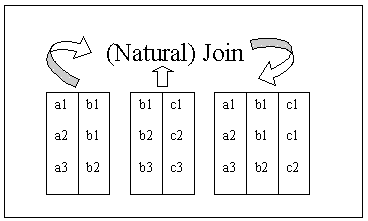
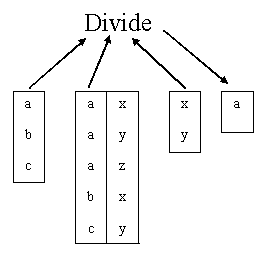
3.4.2 แคลคูลัสเชิงสัมพันธ์ (Relational Calculus)
แคลคูลัสเชิงสัมพันธ์ เป็นเชิงพรรณนา หรือเป็นการระบุนิยามของผลลัพธ์ (Descriptive = To state definition of result) นั่นคือ ผู้เขียนต้องกล่าวถึงผลลัพธ์ที่ต้องการนั้นว่ามีลักษณะหรือรูปร่างหน้าตาอย่างไร แคลคูลัสเชิงสัมพันธ์จึงเป็นการสั่งที่ไม่เป็นโครงสร้าง (Nonprocedural) ตัวอย่างการกำหนดรูปแบบโดยวิธีแคลคูลัส (Calculus Formulation) เช่น สั่งว่า
Get SNO and CITY for suppliers such that there exists a shipment SP with the same SNO value with PNO value P2.
(ให้แสดงข้อมูลของแอตทริบิวต์ SNO และ CITY สำหรับผู้จัดส่งที่มีค่าหมายเลขผู้จัดส่ง (SNO) ในตาราง SP ตรงกันกับ ค่า P2 ในแอตทริบิวต์ PNO)
แคลคูลัสเชิงสัมพันธ์มี 2 ประเภท คือ
1. แคลคูลัสแบบแถว (Tuple Calculus) เป็นการระบุนิยามผลลัพธ์โดยยึดแถวข้อมูลในรีเลชั่นเป็นหลัก โดยกำหนดที่ตัวแปรพิสัย (Range Variables) ตัวอย่างเช่น
RANGEVAR SX RANGES OVER S;
RANGEVAR SY RANGES OVER S;
RANGEVAR SPX RANGES OVER S;
RANGEVAR SPY RANGES OVER S;
RANGEVAR PX RANGES OVER P;
RANGEVAR SU RANGES OVER
(SX WHERE SX.CITY = ‘London’),
(SX WHERE EXISTS SPX (SPX.SNO = SX.SNO AND SPX.PNO = PNO (‘P1’)));
(ให้แสดงข้อมูลของผู้จัดส่งที่อยู่ในกรุงลอนดอน และส่งชิ้นส่วน P1 ไปขาย)
2. แคลคูลัสแบบสดมภ์ (Domain calculus) เป็นการระบุนิยามผลลัพธ์โดยยึดสดมภ์หรือคอลัมน์ของข้อมูลในรีเลชั่นเป็นหลัก โดยกำหนดที่ตัวแปรพิสัย (Range Variables) ตัวอย่างเช่น
SX
SX WHERE S (SNO.SX)
SX WHERE S (SNO:SX, CITY:’LONDON’)
(SX, CITY) WHERE S (SNO:SX, CITY:CITYX)
AND SP (SNO:SX, PNO:PNO(‘P2’)
(ให้แสดงหมายเลขผู้จัดส่งและเมืองของผู้จัดส่งที่ส่งชิ้นส่วย P2)
(SX, PX) WHERE S (SNO:SX, CITY:CITYX)
AND P (PNO:PX, CITY:CITYY)
AND CITYX CITYY
(ให้แสดงคู่ของหมายเลขผู้จัดส่งและหมายเลขชิ้นส่วนของผู้จัดส่งที่เป็นการส่งไปต่างเมือง)
อีกตัวอย่างหนึ่งที่สั้นกว่า เช่น
SX WHERE EXISTS STATUSX
(STATUSX>20 AND
S (SNO:SX, STATUS:STATUSX, CITY: ‘PARIS’))
(ให้แสดงหมายเลขผู้จัดส่งสินค้าเฉพาะรายที่อยู่ในกรุงปารีสที่มีค่าสถานะมากกว่า 20)
3.5 การเลือกใช้ระบบบริหารฐานข้อมูล
ปัจจุบันมีการผลิตระบบบริหารฐานข้อมูลออกมาเป็นจำนวนมาก โดยแต่ละโปรแกรมก็จะมีความสามารถ ประสิทธิภาพ และคุณสมบัติต่างกันไป เช่น ใช้กับคอมพิวเตอร์ประเภทใด ใช้ตัวแบบข้อมูลประเภทใด หรือมีภาษาฐานข้อมูลใดสนับสนุน ดังตารางต่อไปนี้
ชื่อระบบบริหาฐานข้อมูล |
ประเภทคอมพิวเตอร์ |
ตัวแบบข้อมูล |
ภาษาฐานข้อมูล |
DB2 |
Mainframe computer |
Relational |
SQL, OBE |
DBAS/IV |
Microcomputer |
Relational |
SQL, owner’s |
FoxBASE+ |
Microcomputer |
Relational |
owner’s |
FoxPro |
Microcomputer |
Relational |
SQL, owner’s |
IDMS |
Mainframe computer |
Network |
owner’s |
IMS/VS |
Mainframe computer |
Hierarchical |
CICS |
Ingres |
Minicomputer, |
Relational |
SQL, OBE |
Informix |
Super Minicomputer, |
Relational |
SQL, OBE |
Oracle |
Mainframe computer, |
Relational |
SQL |
PARADOX |
Microcomputer |
Relational |
owner’s |
ACCESS |
Microcomputer |
Relational |
owner’s, SQL, OBE |
การที่องค์การจะตัดสินใจเลือกใช้ระบบบริหารฐานข้อมูลยี่ห้อใดนั้นควรพิจารณาตามเกณฑ์ต่าง ๆ ที่ขอเสนอแนะ ดังนี้
1. งบประมาณขององค์การและราคาของระบบบริหารฐานข้อมูลที่ต้องการ เนื่องจากระบบบริหารฐานข้อมูลแต่ละยี่ห้อจะมีราคาแตกต่างกัน ยิ่งมีความสามารถมากก็จะยิ่งแพงมาก ถ้าองค์การมีงบประมาณในการลงทุนด้านไอทีไม่มากพอ อาจจำเป็นต้องพิจารณาใช้ระบบที่มีความสามารถปานกลางแต่รองรับงานขององค์การได้ไปพลางก่อน แล้งจึงหาทางปรับปรุงระบบในโอกาสต่อไป
2. ความเข้ากันได้กับฮาร์ดแวร์ที่มีอยู่ จากในตารางจะพบว่าระบบฐานข้อมูลแต่ละยี่ห้อจะสามารถใช้ได้กับคอมพิวเตอร์ ไม่สามารถใช้ได้กับเครื่องระดับอื่นๆ ได้ ยกเว้นบางยี่ห้ออาจใช้ได้กับเครื่องหลายประเภท การตัดสินใจใช้จึงต้องพิจารณาดูว่าเครื่องคอมพิวเตอร์ที่มีอยู่ในองค์การของเราเป็นเครื่องประเภทใด มีระบบปฏิบัติการอะไร สามารถจะใช้กับระบบบริหารฐานข้อมูลที่ต้องการได้หรือไม่
3. ความน่าเชื่อถือของระบบบริหารฐานข้อมูล คือ ชื่อเสียงของระบบบริหารฐานข้อมูลที่ต้องการให้พิจารณาว่ามีเสถียรภาพเป็นที่ยอมรับในวงกว้างหรือไม่ มีชื่อเสียวมายาวนาน พอสมควรหรือไม่ นอกจากนี้ยังรวมถึงผู้จำหน่ายระบบนั้นด้วยว่ามีความชำนาญในการดูแลระบบดังกล่าวมากน้อยเพียงใด มีความรับผิดชอบต่อลูกค้าหรือไม่ ทำธุรกิจด้านนี้มานานเท่าใด เคยขายระบบให้หน่วยงานอื่นบ้างหรือไม่ มากเพียงใด เป็นต้น
4. ความเร็วในการประมวลผล ระบบบริหารฐานข้มูลแต่ละยี่ห้อ หรือแต่ละรุ่น อาจมีความเร็วในการประมวลผลข้อมูล การค้นหาข้อมูล หรือการเรียงลำดับข้อมูล แตกต่างกันออกไป เมื่อนำมาใช้กับระบบเครื่องคอมพิวเตอร์ในองค์การที่มีอยู่ ต้องมีการทดสอบความสามารถของแต่ละยี่ห้อหรือแต่ละรุ่นว่ามีความเร็วในการทำงานมากน้อยแค่ไหน หรือสามารถจะปรับแต่งระบบให้เร็วขึ้นได้หรือไม่
5. การรักษาความปลอดภัยของระบบฐานข้อมูล เป็นการพิจาณาความสามารถด้านการรักษาความปลอดภัยของระบบบริหารฐานข้อมูลแต่ละตัวว่าน่าเชื่อถือมากน้อยเพียงใด และมีวิธีการรักษาความปลอดภัยอย่างครบถ้วนตามมาตรฐานที่ควรจะมีหรือไม่
6. จำนวนผู้ใช้งานในระบบ ระบบบริหารฐานข้อมูลแต่ละตัวจะอนุญาตให้มีจำนวนผู้ใช้งานในระบบได้มากน้อยไม่เท่ากันตามแต่ขนาดของงาน และตามแต่ขีดจำกัดในการรองรับของระบบแต่ละรุ่น
7. จำนวนแฟ้มข้อมูลและขนาดของระเบียนที่เปิดใช้ เป็นการพิจารณาลักษณะของงานว่าต้องมีการเปิดใช้แฟ้มข้อมูลสูงสุดกี่แฟ้ม แต่ละแฟ้มมีระเบียนขนาดใหญ่ที่สุดเท่าใด แล้วเลือกระบบบริหารฐานข้อมูลที่สามารถรองรับได้
8. ภาษาฐานข้อมูลที่ระบบสนับสนุน จากในตารางข้างต้นจะเห็นว่าระบบบริหารฐานข้อมูลแต่ละระบบมีการใช้ภาษาแตกต่างกันไป ส่วนใหญ่จะมีภาษาสอบถามเชิงโครงสร้าง หรือเอสคิวเอล แต่บางระบบก็ไม่มี แต่จะใช้ภาษาของตนเองซึ่งเราต้องพิจารณาว่าผู้ใช้ควรจะต้องมาศึกษาภาษานั้นให้ชำนาญได้หรือไม่ ใช้เวลานานไหม คุ้มค่าหรือเปล่า เป็นต้น
9. ตัวแบบฐานข้อมูลและความเหมาะสมต่อลักษณะงาน เราต้องพิจารณาว่างานในองค์การของเรานั้นมีการจัดเก็บข้อมูลประเภทใดเป็นหลัก ถ้าเป็นข้อมูลปรกติธรรมดาอย่างองค์การธุรกิจส่วนใหญ่ ก็สมควรจะใช้ระบบที่เป็นแบบเชิงสัมพันธ์ซึ่งเป็นที่นิยมใช้กันมากอยู่แล้ว แต้ถ้างานขององค์การจำเป็นต้องเก็บข้อมูลสื่อประสม (Multimedia) เป็นจำนวนมากเป็นพิเศษแล้ว เราก็ควรพิจารณาใช้ระบบที่เป็นแบบอื่นที่เหมาะสมกว่า เช่น ฐานข้อมูลแบบสื่อประสม (Multimedia Database), ฐานข้อมูลแบบสื่อประสมและสื่อพิเศษ (Multimedia and Hypermedia Database) หรือ ฐานข้อมูลเชิงวัตถุ (Object-oriented Database) เป็นต้น
10. โปรแกรมประกอบอื่น ๆที่ระบบมีให้ เช่น ระบบบริหารฐานข้อมูลนั้นมีโปรแกรมช่วยสร้างรายงาน (Report Generator) ที่มีความสามารถสูงและง่ายต่อการใช้หรือไม่ มีโปรแกรมช่วยสร้างโปรแกรมประยุกต์ (Application Generator) หรือไม่ หรือมีโปรแกรมช่วยออกแบบสร้างรีเลชั่นหรือไม่ เป็นต้น
 |